Case Study
Distributed AI Platform with Real-Time Messaging
01 — Context & Motivation
This project evolved from earlier experimentation with locally hosted AI chatbots. Running a local model behind a web interface such as HuggingFace ChatUI was relatively straightforward, and I initially built small prototypes intended for personal and family use. While functional, these setups were simple in architectural terms and did not present many interesting systems problems.
I became interested in increasing the complexity of the system by separating inference, orchestration, and user interaction across multiple machines. Messaging platforms such as Telegram provided an appealing direction: they act as lightweight frontends, expose well-documented APIs, and integrate naturally into everyday communication. Integrating Telegram was therefore both a technical challenge and a practical experiment in building a system that could operate within a real-world messaging ecosystem rather than a controlled browser environment.
Another motivation was cross-platform coordination. The system now spans Android, Linux, and Windows environments, requiring consistent communication between heterogeneous systems and reinforcing the importance of clearly defined APIs, schemas, and deployment boundaries.
02 — System Architecture
The platform is structured as a multi-node system with clearly separated responsibilities. A Telegram bot running on an Android device (Pixel 7, via Termux) acts as the user-facing interface. Messages are forwarded to a central orchestration server ("brain node," as I refer to it), which validates requests, manages conversation context, and routes inference requests to a dedicated AI node. Responses return through the same path to the Telegram client.
Communication between nodes is implemented using asynchronous FastAPI services over HTTP with JSON payloads. The orchestration layer acts as a controlled boundary, ensuring that all requests pass through validation, readiness checks, and routing logic before reaching the inference service.
Services are containerised using Docker and exposed through an NGINX reverse proxy, simplifying deployment and isolation across machines. Monitoring and readiness checks are integrated with Uptime Kuma, allowing model availability and service health to be observed without manual inspection.
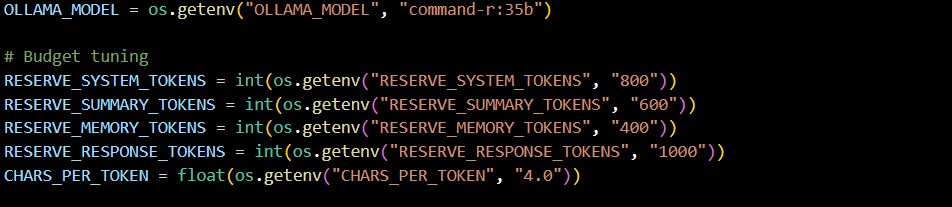
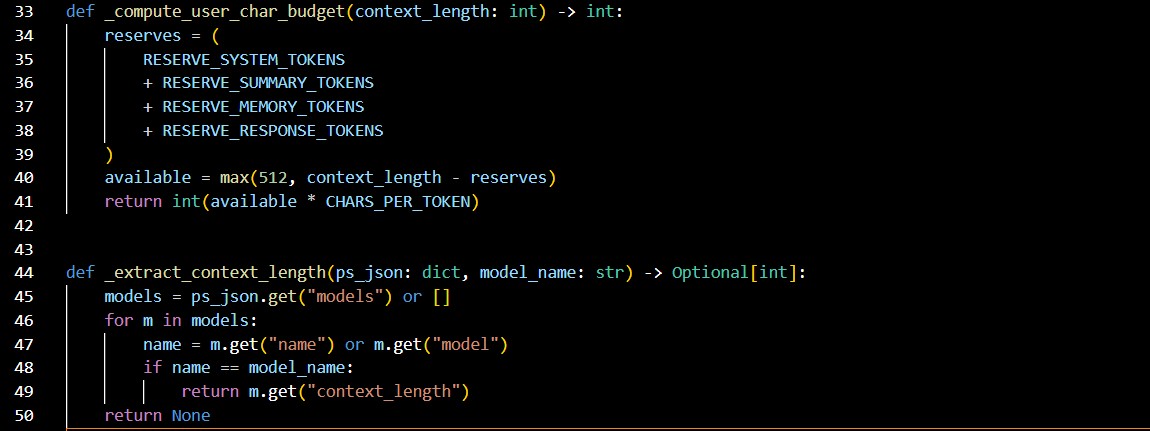
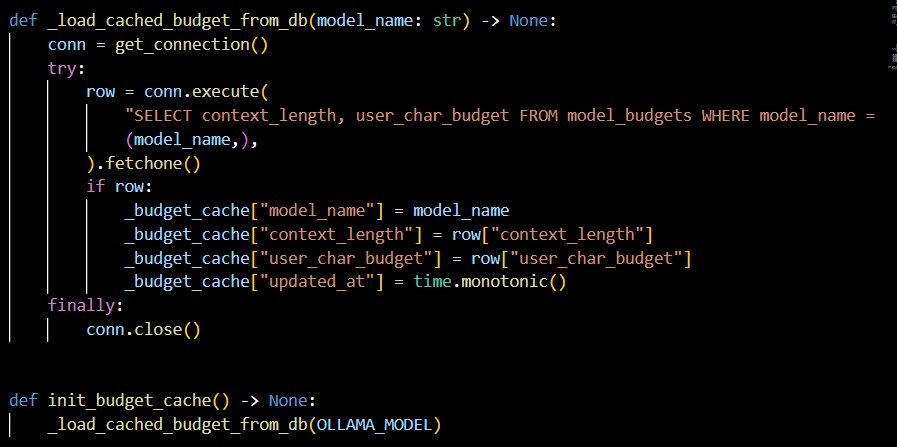
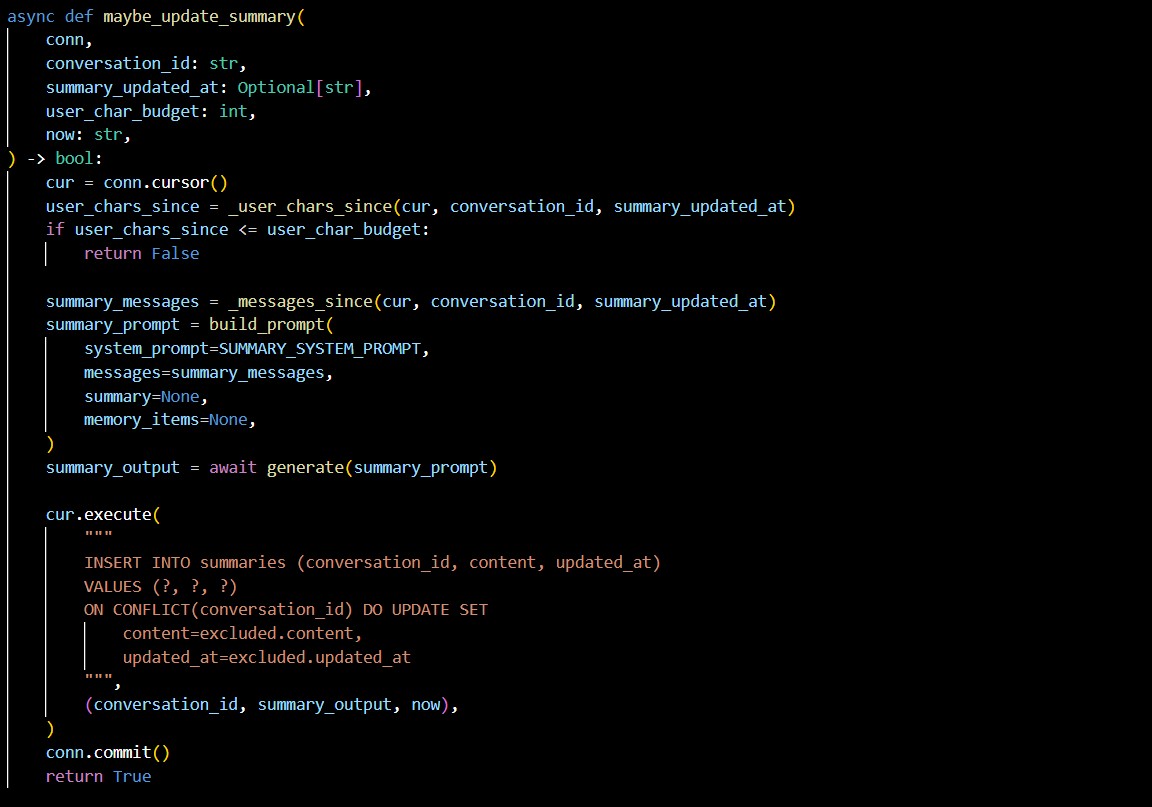
Internally, the system maintains model-specific context budgets. When a model is loaded, its approximate context capacity is estimated by querying the inference service and calculating a character-based budget. Conversation history is managed against this budget, and when limits are exceeded, summarisation is triggered and persisted, allowing long-running conversations to continue without exceeding model constraints.
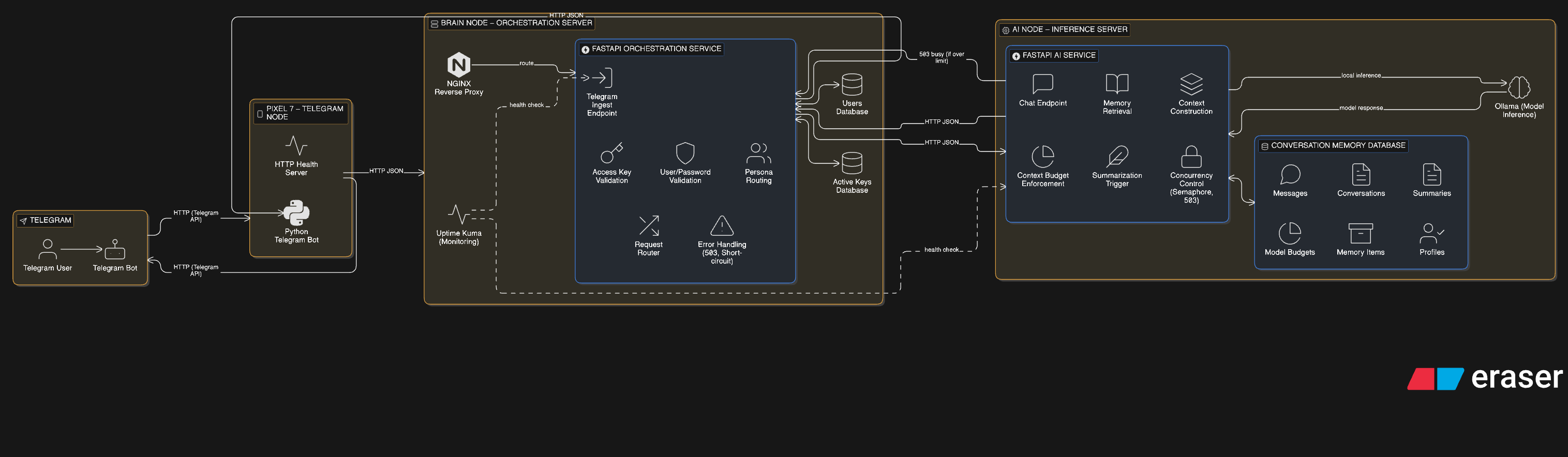
High-level architecture of the distributed AI platform. A Telegram bot running on an Android device forwards user messages to an orchestration service ("brain node"). The brain node performs access validation, persona routing, readiness checks, and request gating before forwarding requests to the inference service ("AI node").
Conversation memory, summaries, and model budget logic are managed on the AI node, allowing context to persist across sessions. Monitoring and health checks are integrated across all components, enabling observability of each service independently.
03 — System Behavior and Request Flow
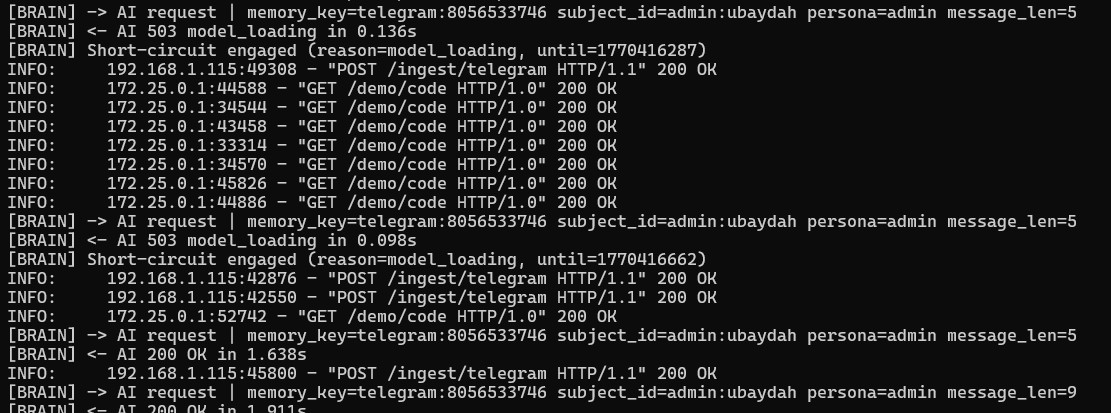
From a user perspective, each interaction looks like a simple chat message. Internally, the request passes through multiple boundaries: the Telegram bot receives the message, forwards it to the orchestration layer, and waits for a response routed back from the inference node.
To keep behavior predictable under load, the brain node performs readiness checks and can short-circuit requests when the model is unavailable. Logs are emitted at each hop, making it possible to trace routing decisions, gating outcomes, and the generation lifecycle across machines.

04 — Design Decisions
One of the most significant design decisions was introducing an orchestration layer rather than allowing the messaging interface to communicate directly with the inference service. This created a clear separation between user interaction, routing logic, and compute-intensive inference, making it possible to evolve each component independently.
Conversation memory was designed around explicit identities and contexts rather than a single global history. Each interaction is associated with a persona, subject identifier, and memory key, allowing multiple users and conversational contexts to coexist safely. Context windows are constructed dynamically using a character-budgeting approach rather than a fixed message count, ensuring predictable memory usage across different models with varying token limits.
Concurrency control was another important consideration. The system currently allows a limited number of concurrent users, with additional requests queued once capacity is reached. Implementing request gating and queue management provided a practical demonstration of concepts that often appear in academic settings but are rarely encountered in small personal projects.
Finally, the decision to run the Telegram bot directly on an Android device introduced additional complexity but provided a realistic test of distributed coordination across heterogeneous systems.


05 — What Works Well / Trade-offs
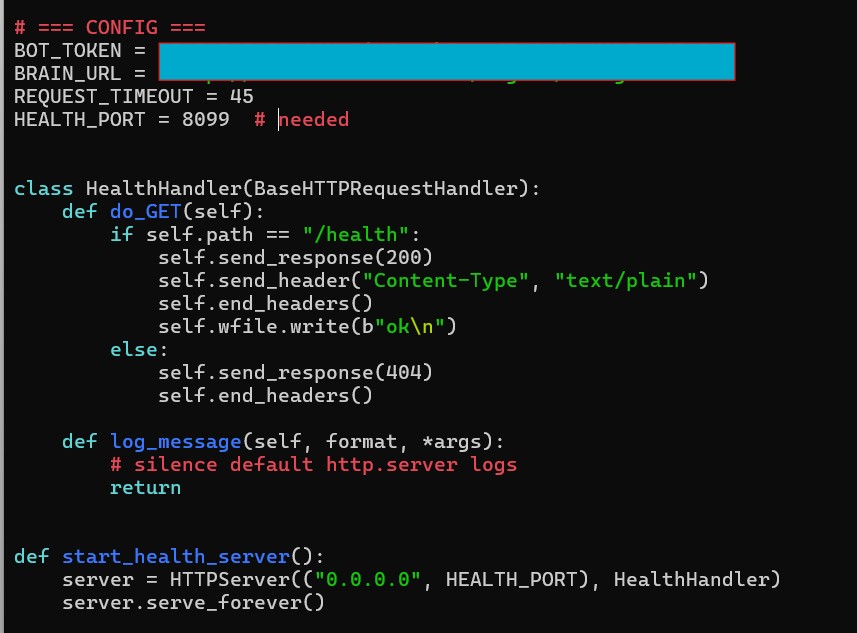
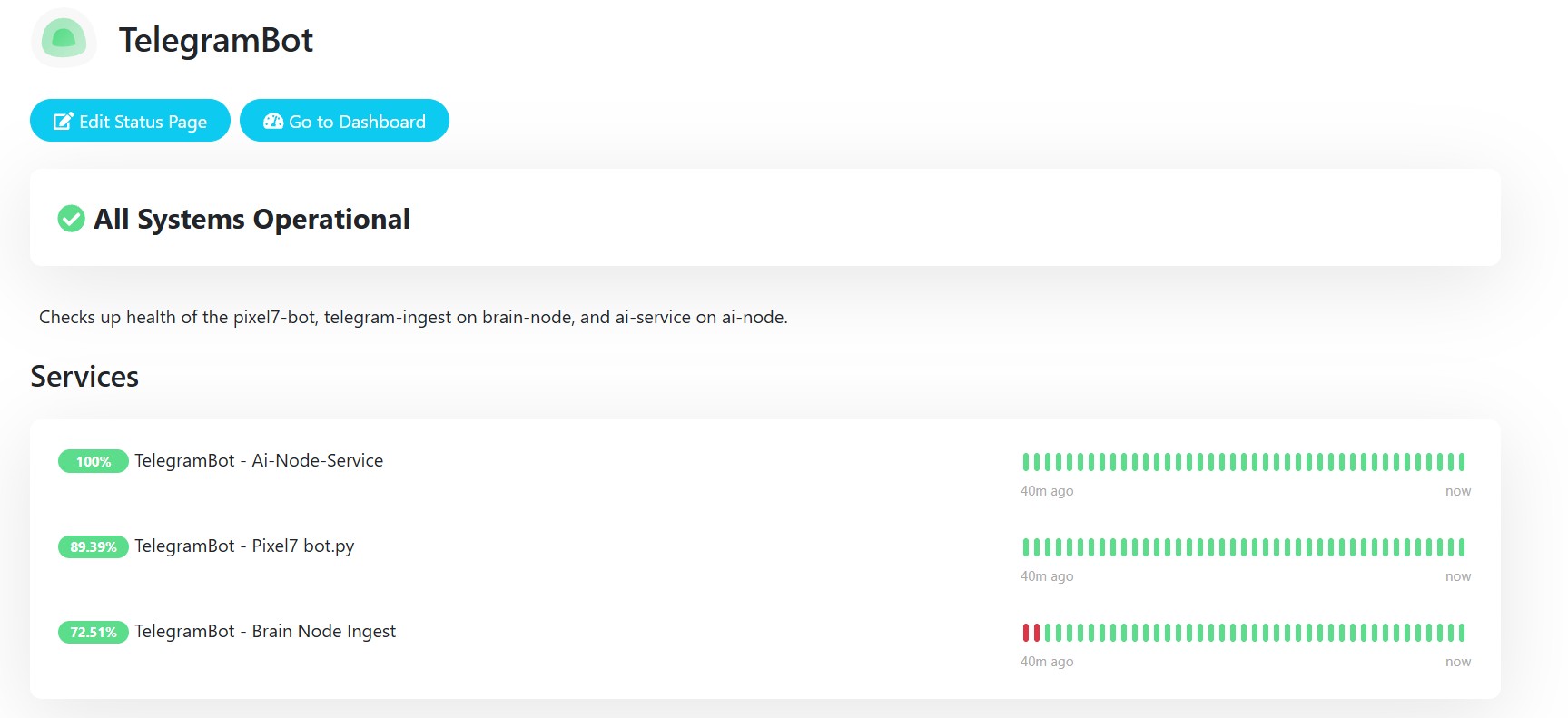
Telegram turned out to be an interesting interface to build against. The Bot API is well documented, and being able to inspect requests and responses in detail made it easier than I expected to understand what was happening at each step. Running the bot on an Android device also made the system feel closer to a real service rather than a prototype, since it was always available and reachable in the same way a normal messaging app is. Observability became an important part of the system as it grew. I added a small HTTP health server directly inside the bot so that Uptime Kuma could monitor it, and because the system was distributed I could monitor the bot, the orchestration layer, and the inference service independently. That monitoring data is even surfaced on the live demo page, which helped turn operational tooling into part of the user-facing experience.
At the same time, working across multiple machines introduced real complexity. Coordinating database schemas and keeping services aligned across the Android bot, brain node, and AI node required careful validation and testing. Container orchestration, environment variables, and network configuration added overhead compared with a single-process design, but that complexity is inherent to distributed systems and was part of the learning process. Queue management and concurrency control were also more involved than expected, particularly when enforcing limits and handling busy responses, but implementing these mechanisms made abstract ideas about scheduling and resource constraints feel concrete in a way small projects rarely do.
06 — Future Improvements
Future work will focus on improving queue management and concurrency handling, particularly as the number of concurrent users increases. More advanced scheduling strategies and better monitoring of request lifecycles would further improve system responsiveness and reliability.
Another planned improvement is voice interaction. Telegram voice messages could be routed through a transcription service such as Faster Whisper, allowing spoken input to be converted to text and processed by the system in the same way as typed messages.
Longer-term exploratory ideas include image parsing and multimodal input, which would extend the system beyond text-only interaction and provide additional opportunities to experiment with distributed inference pipelines.